前回の記事では、python スクリプトを用いてジャーナル website で文献を検索する方法について紹介しました。
第2回目の本記事では、selenium を使ってジャーナル website からあるキーワードを含む新着論文を自動でダウンロードするスクリプトをご紹介します。
今回の記事は、前回よりもスクレイピングっぽい内容になっています。
目次
実行例
まずは、python script で JACS の新着文献で、タイトルにあるキーワードを含んだ論文のみをダウンロードする様子をご覧ください(下動画、全画面表示にすると見やすいと思います)。
上記の例では、論文タイトルに “Activity” という単語が含まれている新着論文を 3 件自動でダウンロードしています。
以下、説明です。
環境設定
python3 をインストールし、time, selenium ライブラリも入れておいて下さい。
また、ご自身がお使いの Web ブラウザの webdriver を導入して下さい。管理人は、Google Chrome を使っているので、こちらのページから chromedriver をダウンロードしました。また、導入の際には、version に注意下さい。
実際のコード
#! /usr/local/bin/python3
import time
from selenium import webdriver
url = "https://pubs.acs.org/toc/jacsat/0/0" #JACS の ASAP ページ
keyword = "Activity" #論文タイトルの検索キーワード
#PDF download 用の設定
download_dir = "/Users/hogehoge/Download/"
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {
"download.default_directory": download_dir,
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"plugins.plugins_disabled": ["Chrome PDF Viewer"],
"plugins.always_open_pdf_externally": True
})
options.add_argument("--disable-extensions")
options.add_argument("--disable-print-preview")
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(2)
PDF = []
for a in driver.find_elements_by_partial_link_text("PDF"):
PDF.append(a.get_attribute("href"))
TITLE = []
for a in driver.find_elements_by_class_name("issue-item_title"):
TITLE.append(a.text + ".pdf")
i = 0
for a in TITLE:
if keyword in a:
driver.get(PDF[i])
time.sleep(2)
i += 1
time.sleep(20)
driver.quit()
以下、このスクリプトについての解説です。
STEP 1 ジャーナルのページにアクセス
スクレイピングでは、BeautifulSoup や urllib.request を import することが多いですが、大変困ったことに ACS 等の website には terminal から直接アクセスすることは出来ません(直接アクセスしようとすると 403 エラーが帰ってきます)。
この問題を回避するために、ブラウザからアクセスする必要があります。そこで、今回は selenium を使います。
今回のコードでは、
url = "https://pubs.acs.org/toc/jacsat/0/0" driver = webdriver.Chrome(options=options) driver.get(url)
でブラウザの起動と、JACS の ASAP ページへのアクセスを行なっています。
STEP 2 ページソースコードを解読(html)
スクレイピングを行うには、必要最低限の html のタグの知識が必要です。(よく使われる html のタグの数は限られているので、普通の人ならばすぐに覚えられると思います。)
JACS の ASAP ページで、各新着論文のタイトルを探す場合を例に解説します。
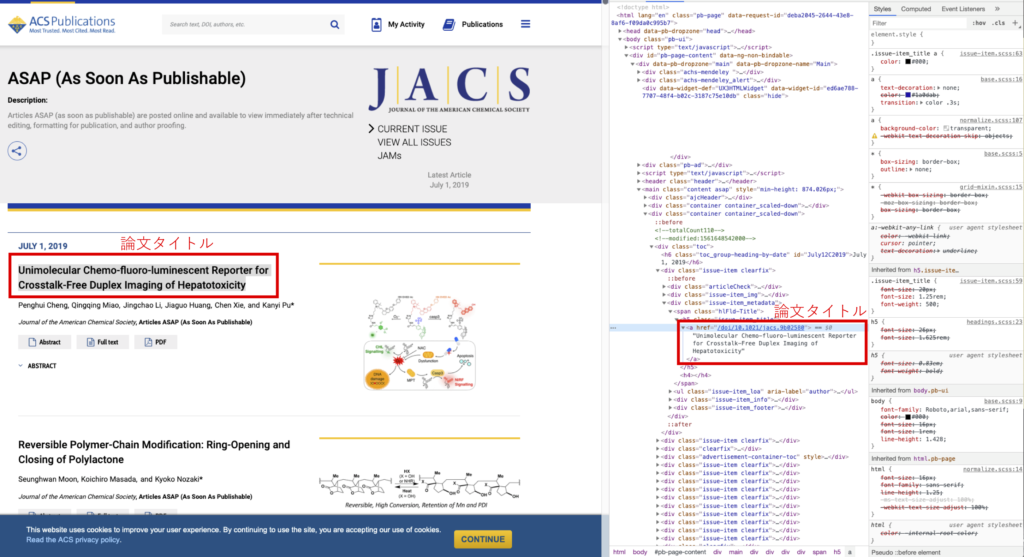
一般的な web ブラウザには検証ツールがついています。右クリックで検証 (Inspect) を選択すると、上記のような画面になります。
JACS の新着論文のページでは、論文タイトルは、全て h5 タグで囲まれています。
また、PDF のボタンは a タグで、 <a title=”PDF” href=”doi number”> のような形式で記述されています。
STEP 3 論文タイトルと DOI を格納
まずは、
driver.find_elements_by_partial_link_text("PDF")
で ページ内の <a title=”PDF” href=”doi number”> を全て検索します。
href の中身だけを抽出するには
a.get_attribute("href"))
を使用します。
そして、PDF という配列に pdf ファイルのリンクアドレスを
PDF.append(a.get_attribute("href"))
で格納していきます。
同様に、論文のタイトルも
driver.find_elements_by_class_name("issue-item_title")
で一括検索します(今回のスクリプトでは、h5 タグではなく、クラス名で検索しています。)
こちらも TITLE という配列に
TITLE.append(a.text)
で格納していきます。
STEP 4 論文をダウンロード
今回のスクリプトでは、最初に keyword という変数を設定しています。今回は、keyword は activity となっています。
各論文タイトルに activity という文字列が含まれているかを
if keyword in a
で一括検索します。
そして、keyword が含まれている場合には pdf ファイルをダウンロードする、という処理は以下のようになります。
i = 0 for a in TITLE: if keyword in a: driver.get(PDF[i]) time.sleep(2) i += 1
ACS の robots.txt には Crawl-delay: 1 と書かれていますので、各論文のダウンロードの間に一秒以上間隔を開けるようにして下さい。今回は、time.sleep(2) で指定しています。
googlechrome で pdf を保存したい場合には、PDB viwer をオフにする方法が早いです。
今回のスクリプトだと、
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", { "download.default_directory": download_dir, "download.prompt_for_download": False, "download.directory_upgrade": True, "plugins.plugins_disabled": ["Chrome PDF Viewer"], "plugins.always_open_pdf_externally": True }) options.add_argument("--disable-extensions") options.add_argument("--disable-print-preview") driver = webdriver.Chrome(options=options)
の部分で、pdb viwer を OFF にしています。
PDB viwer が ON になっていると、そのまま chrome 上で pdf ファイルが開かれてしまいますが、OFF になっていると pdf ファイルを開かずにダウンロードしてくれます。
今回のスクリプトでは、
download_dir = “/Users/hogehoge/Download/”
で保存場所を指定してあります。hogehoge の部分をユーザー名に変更して下さい。
第二回のまとめ
今回の記事では、①自動的にブラウザを起動し、②特定のキーワードの入っている論文のみを検索し、③自動的に pdf ファイルをダウンロードする、というスクリプトを紹介しました。
今回のスクリプトでの pdf ファイルのダウンロードは、購読権のある環境下でのみ実行可能です。そのため、大学や研究所などに常設しているパソコンで実行することをお勧めします。
注意:ジャーナルの購読権の無い方は、このスクリプトを実行しても pdf ファイルをダウンロードすることは出来ません。
このスクリプトを毎週決まった時刻に研究室の計算機などで自動的に実行するように設定してやれば、わざわざジャーナルの website に行って新着文献のチェックをする必要が無くなります。今回は、keyword を一つしか設定しませんでしたが、複数設定することも可能です。
さらに、メールに通知が来るようにしてやれば、より快適になります。(ダウンロードした pdf ファイルをメールに添付することも技術的には可能ですが、ここでは紹介しません。)
次回以降の記事では、ジャーナルのページから特定の情報を検索して成形して出力する方法を紹介したいと思います。例えば、ある研究者の全ての論文の abstract を抽出し、リスト化して出力する、など。
最後に
今回の記事で紹介したスクリプトを実行する際は、自己責任でお願いいたします。また、time.sleep(2) の行を削除して、ジャーナル側のサーバーに負荷がかかるような使い方はしないようお願いいたします。